Agenci AI zaczynają zmieniać sposób, w jaki użytkownicy znajdują informacje, narzędzia i usługi w internecie. Coraz częściej nie chodzi już tylko o to, która strona pojawi się w Google, ale także o to, które zasoby agent AI będzie w stanie odkryć i wykorzystać do wykonania powierzonego mu zadania.
Agentic Resource Discovery, czyli ARD, wpisuje się w kierunek rozwoju AI Search i agentic SEO. Nie jest klasycznym czynnikiem rankingowym Google ani „nowym hackiem SEO”, ale może być jednym z pierwszych standardów pokazujących, jak w przyszłości agenci AI będą odkrywać narzędzia, API, serwery MCP, workflow i inne zasoby dostępne w sieci.
W tym artykule wyjaśniamy, czym jest ARD, jak działa ai-catalog.json, czym różni się od llms.txt i dlaczego marketerzy, SEO-wcy oraz firmy technologiczne powinny obserwować ten standard.
▼ KLUCZOWE WNIOSKI
Co to jest Agentic Resource Discovery?
Agentic Resource Discovery to otwarty protokół odkrywania zasobów agentowych. Oficjalna strona specyfikacji definiuje ARD jako mechanizm, który pozwala klientowi AI zapytać: „Co jest dostępne dla tego zadania?” i otrzymać dopasowane zasoby z usługi discovery.
Zasobem agentowym może być między innymi agent AI, serwer MCP, API, plugin, workflow, skill, canvas, narzędzie developerskie albo katalog innych zasobów.
Microsoft opisuje to jeszcze prościej: ARD pozwala klientowi AI zadać pytanie, jaki zasób może pomóc w danym zadaniu. Odpowiedzią jest zestaw dopasowanych możliwości wraz z informacją, co robią, kto je dostarcza, gdzie się znajdują i jak klient AI może do nich dotrzeć.
Jaki problem rozwiązuje Agentic Resource Discovery?
Dzisiejsi agenci AI często działają tylko z tymi narzędziami, które zostały wcześniej ręcznie podłączone. Jeżeli agent nie ma danego narzędzia w swoim kontekście, konfiguracji albo katalogu, to z jego perspektywy takie narzędzie praktycznie nie istnieje.
Microsoft porównuje ten problem do wczesnego internetu. Strony istniały, ale bez warstwy wyszukiwania ludzie trafiali głównie na to, co mieli już zapisane albo ręcznie skatalogowane. Wyszukiwarki rozwiązały problem odkrywania stron. ARD próbuje rozwiązać podobny problem dla zasobów agentowych.
To ważne, ponieważ ekosystem agentów, narzędzi AI, API i serwerów MCP rośnie szybciej niż możliwość ich ręcznej konfiguracji.
Jeżeli każda firma, aplikacja SaaS albo zespół developerski może publikować własne narzędzia, potrzebna jest wspólna warstwa opisująca, co te narzędzia robią i kiedy powinny być użyte.
Jak działa Agentic Resource Discovery?
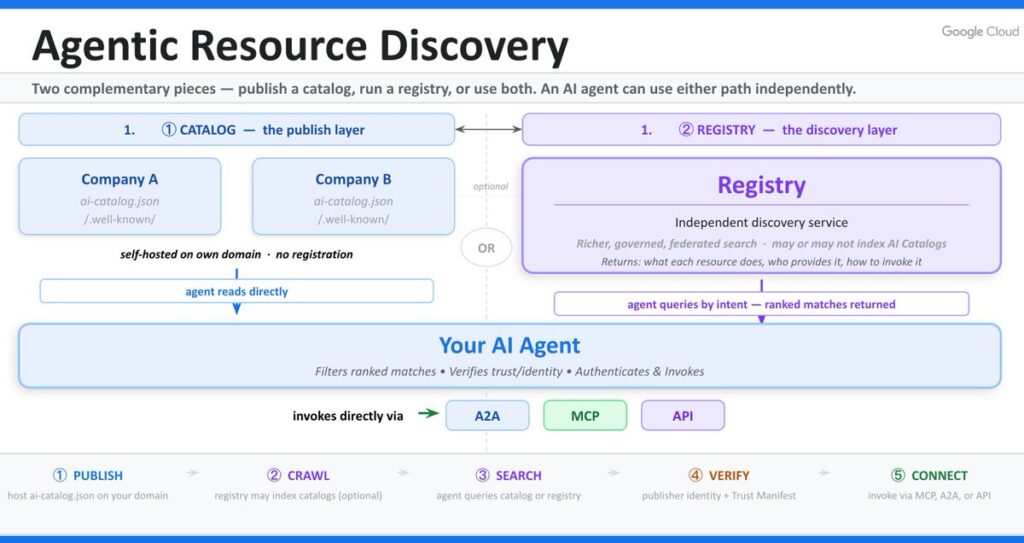
ARD opiera się na dwóch podstawowych elementach:
- katalogach
- rejestrach.
Katalog to plik publikowany przez organizację we własnej domenie. Opisuje on dostępne zasoby: na przykład serwer MCP, API, agenta A2A albo inne narzędzie. Google wyjaśnia, że katalog hostowany pod domeną organizacji daje podstawę do identyfikacji i zaufania, ponieważ zasób jest powiązany z właścicielem domeny.
Rejestr działa jak wyszukiwarka dla agentic web. Rejestry crawlują opublikowane katalogi, indeksują ich zawartość i pozwalają agentom wyszukiwać zasoby. Gdy agent zgłasza potrzebę, rejestr może zwrócić dopasowane możliwości wraz z metadanymi potrzebnymi do weryfikacji wydawcy.
W praktyce proces ARD wygląda w następujący sposób:
- firma publikuje katalog ai-catalog.json w swojej domenie,
- rejestr ARD odkrywa i indeksuje ten katalog,
- agent AI potrzebuje konkretnej funkcji,
- wysyła zapytanie do rejestru,
- rejestr zwraca pasujące zasoby,
- a agent wybiera zasób i łączy się z nim przez jego natywny protokół.
Ważne: ARD nie wykonuje zadania. ARD pomaga znaleźć zasób, który może wykonać zadanie.
Czym jest ai-catalog.json?
Ai-catalog.json to plik, który opisuje zasoby agentowe dostępne w danej domenie. Standardowo taki katalog może być publikowany w dobrze znanej lokalizacji w obrębie domeny organizacji.
Jego celem jest umożliwienie agentom AI i rejestrom discovery zrozumienia, jakie zasoby dana firma udostępnia, do czego one służą i w jakich zadaniach mogą być przydatne.
Taki katalog może zawierać między innymi:
- nazwę organizacji,
- identyfikator wydawcy,
- nazwę zasobu,
- typ zasobu,
- adres zasobu,
- opis funkcji,
- listę możliwości,
- przykładowe zapytania użytkownika lub agenta,
- informacje potrzebne do weryfikacji zaufania.
Dlaczego ARD jest powiązane z SEO?
ARD nie jest klasycznym SEO. Nie optymalizuje title tagów, nie zastępuje linkowania, nie wpływa automatycznie na ranking strony w Google i nie jest obecnie obowiązkowym elementem strategii organicznej.
Jest jednak powiązane z SEO na poziomie szerszej definicji widoczności.
Do tej pory widoczność w internecie oznaczała głównie widoczność strony w Google, widoczność produktu w marketplace, widoczność marki w social media, widoczność firmy w mapach albo widoczność treści w systemach AI, takich jak ChatGPT, Perplexity czy Gemini.
Jeżeli agent AI ma wykonać zadanie, może nie szukać klasycznej strony poradnikowej. Może szukać narzędzia, API, usługi albo agenta, który potrafi wykonać daną operację.
To tworzy nową warstwę konkurencji. W przyszłości firma może rywalizować nie tylko o to, czy jej artykuł pojawi się w Google, ale również o to, czy jej narzędzie, usługa, API albo agent zostanie znaleziony przez klienta AI.
ARD a llms.txt – czym się różnią?
ARD i llms.txt często będą wrzucane do jednego worka z etykietą „AI SEO”, ale to dwa różne mechanizmy:
- Llms.txt jest prostym plikiem tekstowym lub Markdown, który może wskazywać modelom AI najważniejsze informacje i adresy URL na stronie. To raczej przewodnik po treści i strukturze źródła.
- ARD jest mechanizmem odkrywania zasobów agentowych. Nie chodzi tylko o powiedzenie modelowi, które strony są ważne. Chodzi o opisanie konkretnych możliwości, które agent AI może odnaleźć i potencjalnie wykorzystać.
Najprostsze porównanie:
- Sitemap.xml pomaga wyszukiwarkom odkrywać adresy URL.
- Robots.txt pomaga kontrolować dostęp crawlerów.
- Schema.org pomaga strukturalnie opisać dane na stronie.
- Llms.txt może działać jako kuratorowany przewodnik po treści dla modeli AI.
- Ai-catalog.json służy do opisywania zasobów agentowych, które mogą być odkrywane przez agentów AI i rejestry ARD.
Google w swoim poradniku dotyczącym generatywnych funkcji w wyszukiwarce wskazuje, że nie trzeba tworzyć plików takich jak llms.txt, specjalnego markup’u czy Markdown, aby pojawiać się w Google Search, ponieważ Google Search ich nie używa. Jednocześnie Google zaznacza, że utrzymywanie takich plików dla innych usług lub systemów nie szkodzi ani nie pomaga rankingom w Google.
To rozróżnienie jest kluczowe. Llms.txt i ARD mogą mieć sens jako infrastruktura dla innych systemów AI.
ARD a MCP, A2A i API
ARD nie zastępuje MCP, A2A ani API. To częsty błąd interpretacyjny.
MCP, A2A, API albo workflow odpowiadają za wykonanie zadania lub komunikację z narzędziem. ARD odpowiada za odkrycie, że dane narzędzie istnieje i może być właściwe dla danego zadania.
Można to uprościć w poniższy sposób:
- MCP mówi agentowi, jak korzystać z narzędzia.
- API pozwala wykonać konkretną operację.
- A2A pozwala agentom komunikować się między sobą.
- ARD pomaga znaleźć właściwe narzędzie, API albo agenta.
Czyli ARD jest warstwą discovery, a nie warstwą wykonawczą.
Przykład: GitHub Copilot Agent Finder
Jednym z pierwszych konkretnych wdrożeń ARD jest GitHub Agent Finder dla GitHub Copilot. GitHub ogłosił tę funkcję 17 czerwca 2026 roku. Według GitHuba Agent Finder pozwala Copilotowi odkrywać właściwe MCP serwery, skills, canvases, agentów i narzędzia dla danego zadania, zamiast ręcznie podpinać wszystko z góry i zaśmiecać okno kontekstu.
To dobry przykład pokazujący, dlaczego ARD może być ważne. Agent nie musi mieć od razu wszystkich narzędzi w kontekście. Może znaleźć je wtedy, gdy są potrzebne.
Kto powinien interesować się ARD?
Na dziś ARD jest najbardziej istotne dla firm, które mają coś więcej niż klasyczną stronę informacyjną.
Największy sens może mieć dla SaaS-ów, firm z publicznym API, dostawców narzędzi AI, firm tworzących serwery MCP, platform developerskich, marketplace’ów narzędzi, firm B2B z rozbudowaną dokumentacją techniczną, organizacji z własnymi agentami AI oraz firm, które chcą być odkrywane przez agentów jako dostawcy konkretnych funkcji.
Dla typowej strony usługowej bez API, MCP, agenta albo narzędzia wdrożenie ARD może być dziś przedwczesne. Nie oznacza to jednak, że temat można ignorować. Warto go obserwować, bo może stać się częścią większego trendu: przejścia od optymalizacji stron do optymalizacji zasobów i zadań.
Jak przygotować stronę pod Agentic Resource Discovery?
Pierwszy krok nie polega na stworzeniu pliku. Pierwszy krok polega na odpowiedzi na pytanie: jaki zasób agent AI miałby znaleźć na naszej stronie? Jeżeli firma nie ma żadnego zasobu, który agent może wywołać, sam plik ai-catalog.json będzie pustym gestem technicznym.
Przed wdrożeniem warto ustalić:
- czy mamy API, narzędzie, workflow, agenta, dokumentację albo MCP server,
- jaki problem użytkownika lub agenta rozwiązuje ten zasób,
- dla jakich zapytań w języku naturalnym zasób powinien być odkrywany,
- czy zasób ma jasny opis, typ, adres i sposób wywołania,
- czy możemy powiązać zasób z domeną i zaufaniem do wydawcy,
- czy wdrożenie nie obiecuje czegoś, czego zasób realnie nie wykonuje.
Checklista wdrożenia ai-catalog.json
Oficjalny poradnik ARD opisuje trzy podstawowe kroki: utworzenie manifestu, hostowanie go w domenie i opcjonalną konfigurację DNS discovery.
Praktyczna checklista:
- Stwórz listę realnych zasobów agentowych.
- Dla każdego zasobu przygotuj nazwę, opis, typ, adres i listę możliwości.
- Dodaj kilka representative queries.
- Upewnij się, że opis zasobu nie jest marketingowym sloganem, tylko konkretną informacją o funkcji.
- Umieść katalog w zalecanej lokalizacji w domenie.
- Serwuj katalog przez HTTPS.
- Zadbaj o poprawny typ odpowiedzi serwera.
- Umożliwiaj odczyt katalogu przez usługi discovery.
- Zweryfikuj poprawność manifestu.
- Monitoruj, czy pojawiają się rejestry lub narzędzia, które faktycznie korzystają z ARD.
Jak pisać Representative Queries?
Representative queries mogą stać się jednym z najważniejszych elementów z perspektywy widoczności w rejestrach agentowych. To nie powinny być pojedyncze słowa kluczowe. To powinny być naturalne zapytania opisujące zadania, które agent lub użytkownik chce wykonać.
Zamiast ogólnych haseł typu „SEO”, „AI” albo „audyt”, lepiej opisać realne zadania:
- „Przeprowadź audyt widoczności strony w AI Search”.
- „Znajdź problemy techniczne SEO, które mogą ograniczać ruch organiczny”.
- „Sprawdź, czy moja marka jest cytowana w odpowiedziach AI”.
- „Porównaj widoczność mojej firmy w Google i systemach AI”.
To przypomina przejście od słów kluczowych do intencji i zadań. W klasycznym SEO często pytamy: „na jakie frazy chcemy rankować?”. W ARD pytanie może brzmieć: „dla jakich zadań agent powinien odnaleźć nasz zasób?”.
Podsumowanie
Agentic Resource Discovery to nie jest kolejny plik, który automatycznie poprawi widoczność w Google. To specyfikacja dla świata, w którym agenci AI samodzielnie szukają narzędzi, API, agentów i zasobów potrzebnych do wykonania zadania.
Dla agencji SEO oznacza to ważną zmianę myślenia. Widoczność nie będzie dotyczyć wyłącznie stron internetowych, ale również funkcji, możliwości i zasobów, które mogą zostać odnalezione przez systemy AI.
Llms.txt pomaga opisać najważniejsze treści i strukturę źródła dla modeli AI. Ai-catalog.json w ARD może pomagać agentom odkrywać konkretne zasoby, które mogą zostać użyte w działaniu. To dwie różne warstwy tej samej większej zmiany: internetu, w którym nie tylko ludzie i wyszukiwarki odczytują strony, ale również agenci AI wykonują zadania na podstawie dostępnych zasobów.
Dlatego ARD warto znać już teraz. Nie jako gotowy ranking factor, ale jako sygnał kierunku, w którym może rozwijać się AI Search, agentic SEO i techniczna widoczność marek w systemach sztucznej inteligencji.
Źródła wiedzy
- Google Developers Blog – ogłoszenie specyfikacji Agentic Resource Discovery i opis katalogów, rejestrów oraz ai-catalog.json.
https://developers.googleblog.com/announcing-the-agentic-resource-discovery-specification/ - Microsoft Command Line – wyjaśnienie, dlaczego ARD jest warstwą discovery dla zasobów agentowych i czym różni się od zwykłego wyszukiwania.
https://commandline.microsoft.com/agentic-resource-discovery-specification-ard/ - Oficjalna strona Agentic Resource Discovery – definicja ARD, definicja zasobu agentowego i informacja, że ARD działa przed wywołaniem zasobu.
https://agenticresourcediscovery.org/ - Oficjalny poradnik ARD „How to publish” – instrukcja tworzenia i hostowania ai-catalog.json, w tym representative queries, HTTPS, Content-Type i CORS.
https://agenticresourcediscovery.org/how_to_publish/ - AI Catalog Standard – standardowa lokalizacja ai-catalog.json oraz podstawowe elementy manifestu.
https://agenticresourcediscovery.org/ai_catalog_spec/ - GitHub Changelog – Agent Finder dla GitHub Copilot jako przykład wdrożenia ARD.
https://github.blog/changelog/2026-06-17-agent-finder-for-github-copilot-now-available/
- Co to jest Agentic Resource Discovery?
- Jaki problem rozwiązuje Agentic Resource Discovery?
- Jak działa Agentic Resource Discovery?
- Czym jest ai-catalog.json?
- Dlaczego ARD jest powiązane z SEO?
- ARD a llms.txt – czym się różnią?
- ARD a MCP, A2A i API
- Przykład: GitHub Copilot Agent Finder
- Kto powinien interesować się ARD?
- Jak przygotować stronę pod Agentic Resource Discovery?
- Checklista wdrożenia ai-catalog.json
- Jak pisać Representative Queries?
- Podsumowanie
- FAQ
- Źródła wiedzy